
How does the Pink Trombone work?
Published:
The Pink Trombone is a fun, interactive vocal synthesizer written entirely with JavaScript and the Web Audio API. There are no samples involved – all of the sound is generated from scratch in less than 700 lines of code, excluding the user interface. Amazingly, that is enough to synthesize intelligible vowels and consonants, and to control the intensity, pitch, and breathiness of the voice. What exactly is going on inside there? In this blog post, we’ll take a look at some of the concepts that make the Pink Trombone work, and how they’re related to the actual process of human voice production.
The Source-Filter Model
The Pink Trombone is an example of a source-filter model. The basic idea of decomposing a sound into a source (or excitation) shaped by a filter (or resonator) can be intuitively related to musical instruments; think of the vibrating reed in the mouthpiece of a saxophone, and how its sound is shaped by the open or closed holes of the body.
In the human voice, the source is produced by the lungs pushing air through the vocal cords. These are muscles that we can control – if we tense them while air is passing through them, they start to vibrate, and we start to produce voice!
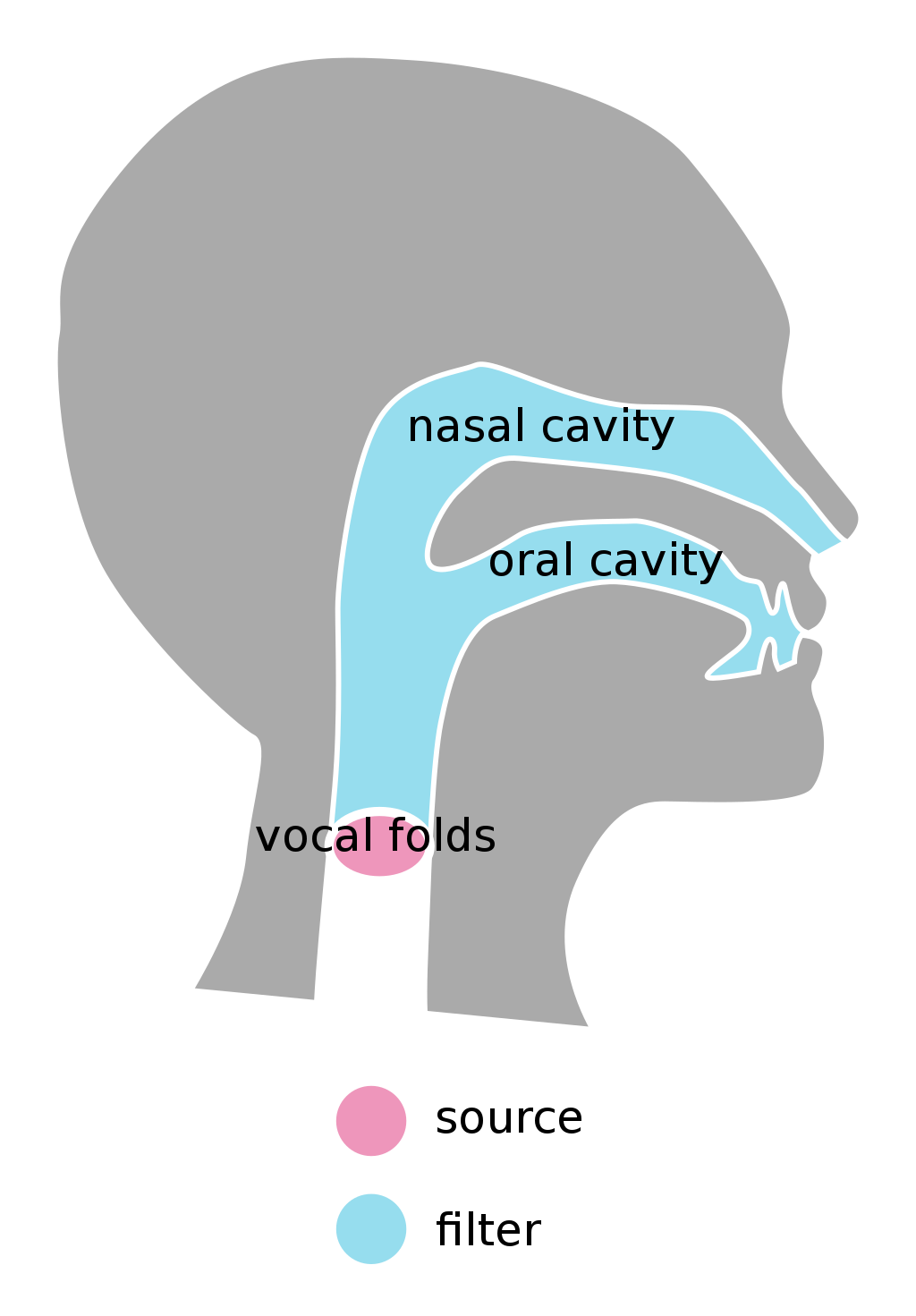
Illustrated Source-Filter Model1
These vibrations then pass through the vocal tract – the filter part of the model. In our nose and mouth, the sound coming from the vocal cords is “shaped” into all the different vowels and consonants making up speech, and given the characteristic sound that makes us uniquely identifiable to others just by our voice.
While both the source-filter model and the specific models for the glottis and the vocal tract make a large number of simplifying assumptions, the Pink Trombone is a great demonstration of how they are more than powerful enough to synthesize a recognizable human voice! We’ll now take a closer look at how the Pink Trombone actually implements these concepts.
The Glottal Source
The source signal of the glottis – the gap between the vocal cords – is essentially generated through wavetable synthesis. A single period of the wavetable corresponds to one glottal cycle, which consists of the following steps:
- The vocal cords are closed and tensed at the beginning of the cycle
- Air pressure from the lungs builds up below the closed vocal cords
- Eventually the pressure is strong enough to blow the vocal cords apart very briefly, releasing a puff of air
- The vocal cords snap back to their closed position due to elasticity and muscle tension
This process repeats many times per second, leading to a periodic signal. The Pink Trombone uses a mathematical model called the Liljencrants-Fant (LF) model to describe the air flow through the vocal cords over the course of a glottal cycle. Actually, it does not model the air flow directly, but rather its derivative, which is what ends up reaching your ears as sound. If you have JavaScript enabled, you can view and listen to the “pure” source signal generated by the LF model below!
Notice the sharp “kink” in the waveform; that’s where the vocal cords snap back to the closed position. If you reduce the “tenseness” of the vocal cords, they will snap back both less sharply and later in the cycle. A sharper waveform also leads to a “sharper” sound.
Just like a buzzing reed doesn’t sound much like a saxophone, this LF model doesn’t sound too human yet – we still have to filter the source through…
The Vocal Tract
Air waves coming from the glottis eventually make their way to the lips and nostrils, where they are released into the wild for others to hear. Everything they pass through on their way is referred to as the “vocal tract”. While the shape of the nose is relatively static, we have great amounts of control over the shape of the mouth, mostly through moving our tongue, jaw, and lips.
The Pink Trombone’s vocal tract is implemented as a Kelly-Lochbaum model. This model dates back to the 1950s and was used in what is considered the first ever computer-generated singing!
Conceptually, the tract is modeled as a series of cylinders, each with a different diameter. Although the Pink Trombone interface suggests two-dimensional control, the KL model is actually just one-dimensional. The Pink Trombone UI gives you high-level control over the shape of the tongue, which is then internally converted into the diameters of the different segments.
The air waves from the glottis are propagated from segment to segment. Everytime the diameters change between segments, the waves are reflected and refracted – this is the basic idea of how the KL model shapes the glottal source. Different tract shapes result in different resonant frequencies (or formants), which makes us recognize the sound as specific vowels. Try it out below - each of the 44 segments is individually adjustable by clicking and dragging, or use the buttons to produce specific vowel sounds!
At the segment marked in red, the oral cavity is connected to the nasal cavity, which is modeled as an additional static KL model. The segment marked in green is the very last segment and corresponds to the lips; if you close that segment completely, the sound will be very muffled.
And that’s it – that’s the basic source-filter model that makes the Pink Trombone work! The actual application implements a number of additional features to make it a complete speech model:
- A noise source added to the glottal source to simulate “breathiness”
- Small pitch fluctuations and vibrato to make the voice sound more natural
- Another noise source in the vocal tract for fricative sounds like ‘v’ and ‘f’
- Collisions – when the vocal tract is too narrow for the glottal source to pass through, the sound is “stopped” and a “click” is added to the output, to produce consonant sounds like ‘k’.
If you want to dive further into those details, you can check out the academic papers that describe the glottal source2 and the vocal tract3 model.
Source-filter model diagram by Emflazie, licensed under CC BY-SA 4.0 ↩
Lu, Hui-Ling, and J. O. Smith. “Glottal source modeling for singing voice synthesis.” Proceedings of the 2000 International Computer Music Conference. 2000. ↩
Story, Brad H. “A parametric model of the vocal tract area function for vowel and consonant simulation.” The Journal of the Acoustical Society of America 117.5 (2005): 3231-3254. ↩
{kind=link}