DDSP Vocal Effects Supplement
Vocoding Approach
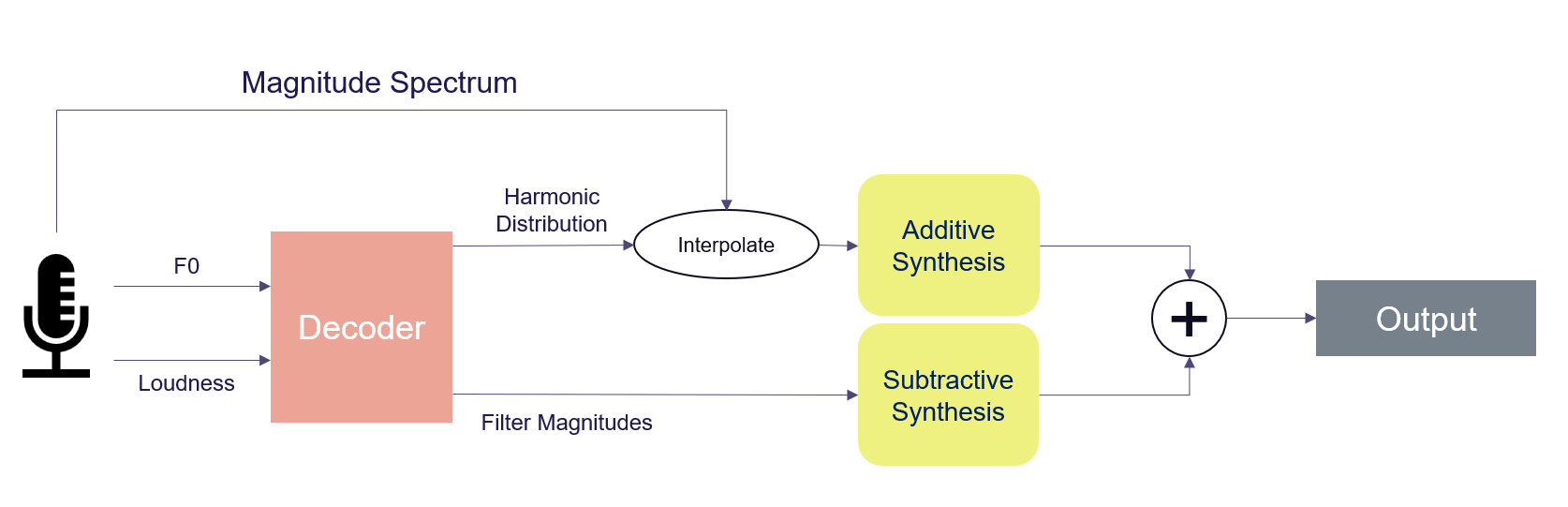
Below are a number of audio examples that demonstrate the vocoding approach, i.e. modifying the harmonic distribution generated from a timbre transfer decoder. Two models were used; on trained on brass instruments, and another on a harsh synthesizer. For every example, the interpolating parameter p is indicated.
All examples were generated from the same input:
Brass
Synth
Latent Approach
The following audio examples demonstrate the latent approach. They were generated from the same input sample as the vocoding examples.
First, the output of a model trained on a dataset consisting of a single person singing children’s songs:
Next, the output of a model trained on a combined dataset of the children’s songs recordings and brass instruments. Early on in the training, the model still struggles to reproduce intelligible lyrics:
As the training progresses, the reproduced lyrics become clearer, but the timbre still seems to be affected by the amended dataset:
When the training continues beyond this point, the model learns to reconstruct the singing voice portion of the training dataset more and more accurately. Eventually, the effect of the additional instruments fades and the output becomes quite similar to that of the model only trained on the singing voice: